Kubernetes Pod pending 很久问题分析及解决
背景
在 IDE 运行过程中,会启动一个 deployment 用做工作空间,然后在 pod ide-server。但是当性能压测的时候,出现了问题。
问题
当 ns 下存在 5w deployment 时,启动 500 个 Pod 从 create 到 running 耗时 5分30秒。不满足需求,需要优化。
现象
feiyan-1000000000 ws-cr3ipb4uccam7di1b9u0-6dbf68f48c-z6vc6 0/1 Pending 0 2m50s <none> <none> <none> <none>
feiyan-1000000000 ws-cr3ipb4uccam7di1b9u0-6dbf68f48c-zcbqn 0/1 Pending 0 2m52s <none> <none> <none> <none>
feiyan-1000000000 ws-cr3ipb4uccam7di1b9u0-6dbf68f48c-zfz8g 0/1 Pending 0 2m49s <none> <none> <none> <none>
feiyan-1000000000 ws-cr3ipb4uccam7di1b9u0-6dbf68f48c-zml6s 0/1 Pending 0 2m50s <none> <none> <none> <none>
feiyan-1000000000 ws-cr3ipb4uccam7di1b9u0-6dbf68f48c-zmmql 0/1 Pending 0 2m52s <none> <none> <none> <none>
Name: ws-cr3ipb4uccam7di1b9u0-6dbf68f48c-zmmql
Namespace: feiyan-1000000000
Priority: 0
Service Account: default
Node: <none>
Labels: app.kubernetes.io/instance=ws-cr3ipb4uccam7di1b9u0
app.kubernetes.io/name=ws-cr3ipb4uccam7di1b9u0
plugin=code-server
pod-template-hash=6dbf68f48c
workspace=ws-cr3ipb4uccam7di1b9u0
Annotations: <none>
Status: Pending
IP:
IPs: <none>
Controlled By: ReplicaSet/ws-cr3ipb4uccam7di1b9u0-6dbf68f48c
Containers:
code-server:
Image: eps-beijing.cr.xxx.com/infcprelease/ide-server:v1.4.0-2408131650
Port: 8910/TCP
Host Port: 0/TCP
Args:
server
--config=/etc/feiyan/config.yaml
--webide-workspace-id=cr3ipb4uccam7di1b9u0
Limits:
cpu: 2
memory: 4Gi
Requests:
cpu: 500m
memory: 512Mi
Liveness: http-get http://:http/healthz%3Ftype=liveness delay=0s timeout=1s period=10s #success=1 #failure=3
Readiness: http-get http://:http/healthz%3Ftype=readiness delay=0s timeout=1s period=10s #success=1 #failure=3
Environment:
USER_ID: 189331
GROUP_ID: 334242
WS_HOME: /home/runner/code
WS_ID: cr3ipb4uccam7di1b9u0
HOME: /home/runner
Mounts:
/etc/feiyan from config (ro)
/home/runner/code from ws-path (rw)
/nix from nix (rw)
/var/run/secrets/kubernetes.io/serviceaccount from default-token-bj4kb (ro)
Volumes:
ws-path:
Type: HostPath (bare host directory volume)
Path: /shared/ws/1000000000/luo
HostPathType: Directory
config:
Type: ConfigMap (a volume populated by a ConfigMap)
Name: feiyan-config
Optional: false
nix:
Type: HostPath (bare host directory volume)
Path: /shared/nix/nix
HostPathType: Directory
default-token-bj4kb:
Type: Secret (a volume populated by a Secret)
SecretName: default-token-bj4kb
Optional: false
QoS Class: Burstable
Node-Selectors: <none>
Tolerations: node.kubernetes.io/not-ready:NoExecute op=Exists for 300s
node.kubernetes.io/unreachable:NoExecute op=Exists for 300s
Events: <none>
发现 event 是空的
常规检查
- Node 资源足够。(未出现任何 node 压力)。排除资源不够的可能性。
- 查看 Pod 状态。
查看 kube-scheduler 日志,发现调度一个 Pod 需要 700ms 左右。500 * 700ms = 350s,光是调度就需要花费350s,太慢了。
I0827 18:35:36.050146 1 trace.go:205] Trace[401520597]: "Scheduling" namespace:feiyan-1000000000,name:ws-cr48mgc00l3h770u0880-78b6b5bf5c-brl62 (27-Aug-2024 18:35:35.424) (total time: 625ms):
Trace[401520597]: ---"Prioritizing done" 625ms (18:35:00.050)
Trace[401520597]: [625.270367ms] [625.270367ms] END
I0827 18:35:36.813014 1 trace.go:205] Trace[1574660176]: "Scheduling" namespace:feiyan-1000000000,name:ws-cr48mgb1lsr0vb3dkji0-8645fd9665-wmvw9 (27-Aug-2024 18:35:36.050) (total time: 762ms):
Trace[1574660176]: ---"Prioritizing done" 762ms (18:35:00.812)
Trace[1574660176]: [762.728076ms] [762.728076ms] END
I0827 18:35:37.460196 1 trace.go:205] Trace[1439543403]: "Scheduling" namespace:feiyan-1000000000,name:ws-cr48mgb1lsr0vb3dkjm0-84c544f4b7-b4kcp (27-Aug-2024 18:35:36.813) (total time: 647ms):
Trace[1439543403]: ---"Prioritizing done" 646ms (18:35:00.460)
Trace[1439543403]: [647.020389ms] [647.020389ms] END
I0827 18:35:38.140289 1 trace.go:205] Trace[980518911]: "Scheduling" namespace:feiyan-1000000000,name:ws-cr48mg3lpur1r9npv5vg-76b6b8c9d5-5n8wb (27-Aug-2024 18:35:37.460) (total time: 679ms):
Trace[980518911]: ---"Prioritizing done" 679ms (18:35:00.140)
Trace[980518911]: [679.90811ms] [679.90811ms] END
从 kube-scheduler 入手
既然处理慢,我们就来看看做了什么。
// Schedule tries to schedule the given pod to one of the nodes in the node list.
// If it succeeds, it will return the name of the node.
// If it fails, it will return a FitError error with reasons.
func (g *genericScheduler) Schedule(ctx context.Context, fwk framework.Framework, state *framework.CycleState, pod *v1.Pod) (result ScheduleResult, err error) {
trace := utiltrace.New("Scheduling", utiltrace.Field{Key: "namespace", Value: pod.Namespace}, utiltrace.Field{Key: "name", Value: pod.Name})
defer trace.LogIfLong(100 * time.Millisecond)
...
trace.Step("Snapshotting scheduler cache and node infos done")
...
trace.Step("Computing predicates done")
...
trace.Step("Prioritizing done")
return ScheduleResult{
SuggestedHost: host,
EvaluatedNodes: len(feasibleNodes) + len(filteredNodesStatuses),
FeasibleNodes: len(feasibleNodes),
}, err
}
从日志上分析,打印了两行日志。 [] "Snapshotting scheduler cache and node infos done" [] "Computing predicates done" [x] "Prioritizing done" [x] "Scheduling" namespace:feiyan-1000000000,name:ws-cr48meotaisig5m53nc0-584fbb955c-qpppn 打印顺序是这样的,说明前面两步不耗时,后边两部耗时久。看看从 "Computing predicates done" 到 "Prioritizing done" 之间做了什么。看了代码,是 prioritizeNodes 方法在执行。看源代码是运行了许多 plugin。
登陆 master node,修改 kube-scheduler 配置
我们先把所有的 plugin 都禁用,发现调度很快。 后来,当我们一个一个插件排除的时候,发现了罪魁祸首。PodTopologySpread
root@ncp3cnq6q0djb2ejvfct0:/etc/kubernetes/manifests# cat /etc/kubernetes/scheduler/kubescheduler-config.yaml
---
apiVersion: kubescheduler.config.k8s.io/v1beta1
clientConnection:
acceptContentTypes: application/json
burst: 100
contentType: application/vnd.kubernetes.protobuf
kubeconfig: /etc/kubernetes/scheduler.conf
qps: 50
enableContentionProfiling: false
enableProfiling: false
healthzBindAddress: 0.0.0.0:10251
kind: KubeSchedulerConfiguration
leaderElection:
leaderElect: true
leaseDuration: 15s
renewDeadline: 10s
resourceLock: leases
resourceName: kube-scheduler
resourceNamespace: kube-system
retryPeriod: 2s
metricsBindAddress: 0.0.0.0:10251
parallelism: 16
percentageOfNodesToScore: 0
podInitialBackoffSeconds: 1
podMaxBackoffSeconds: 10
profiles:
- schedulerName: default-scheduler
plugins:
queueSort:
enabled:
- name: Coscheduling
disabled:
- name: "*"
preFilter:
enabled:
- name: Coscheduling
- name: GPUShare
filter:
enabled:
- name: GPUShare
postFilter:
enabled:
- name: Coscheduling
score:
enabled:
- name: RequestedToCapacityRatio
weight: 4
disabled:
- name: NodeResourcesLeastAllocated
permit:
enabled:
- name: Coscheduling
reserve:
enabled:
- name: Coscheduling
- name: GPUShare
preBind:
enabled:
- name: GPUShare
postBind:
enabled:
- name: Coscheduling
pluginConfig:
- name: Coscheduling
args:
permitWaitingTimeSeconds: 10
deniedPGExpirationTimeSeconds: 3
kubeConfigPath: /etc/kubernetes/scheduler.conf
- name: GPUShare
args:
policy: binpack
weightOfCore: 20
scheduleMode: index
maxContainersPerCard: 16
- name: RequestedToCapacityRatio
args:
shape:
- utilization: 0
score: 10
- utilization: 100
score: 0
resources:
- name: vke.volcengine.com/mgpu-core
weight: 1
- name: vke.volcengine.com/mgpu-memory
weight: 4
- name: cpu
weight: 1
- name: memory
weight: 1
有意思的是,kube-scheduler 是静态 Pod,由 kubelet 拉起来的,启动方法和常规不同。
root@ncp3cnq6q0djb2ejvfct0:/etc/kubernetes/manifests# ls -alh /etc/kubernetes/manifests
total 28K
drwxr-xr-x 2 root root 4.0K Aug 29 18:17 .
drwxr-xr-x 5 root root 4.0K Aug 29 18:17 ..
-rw------- 1 root root 2.7K May 17 11:17 etcd.yaml
-rw------- 1 root root 4.8K Aug 27 21:04 kube-apiserver.yaml
-rw------- 1 root root 3.8K Aug 27 18:26 kube-controller-manager.yaml
-rw------- 1 root root 2.1K Aug 27 21:04 kube-scheduler.yaml
root@ncp3cnq6q0djb2ejvfct0:/etc/kubernetes/manifests#
当把 kube-scheduler.yaml 移出 manifests 目录,kube-scheduler pod 会自动销毁。移动回来,则会新建出来。
root@ncp3cnq6q0djb2ejvfct0:/etc/kubernetes/manifests# ls
etcd.yaml kube-apiserver.yaml kube-controller-manager.yaml kube-scheduler.yaml
root@ncp3cnq6q0djb2ejvfct0:/etc/kubernetes/manifests# kubectl get pods -n kube-system | grep sche
kube-scheduler-192.168.160.103 1/1 Running 0 80m
kube-scheduler-192.168.161.127 1/1 Running 0 76m
kube-scheduler-192.168.161.254 1/1 Running 2 106m
scheduler-controller-manager-5479cd5fbf-8bhgk 1/1 Running 0 104d
scheduler-controller-manager-5479cd5fbf-lgpqz 1/1 Running 0 104d
root@ncp3cnq6q0djb2ejvfct0:/etc/kubernetes/manifests# mv kube-scheduler.yaml ../
root@ncp3cnq6q0djb2ejvfct0:/etc/kubernetes/manifests# kubectl get pods -n kube-system | grep sche
kube-scheduler-192.168.160.103 1/1 Running 0 80m
kube-scheduler-192.168.161.254 1/1 Running 2 106m
scheduler-controller-manager-5479cd5fbf-8bhgk 1/1 Running 0 104d
scheduler-controller-manager-5479cd5fbf-lgpqz 1/1 Running 0 104d
root@ncp3cnq6q0djb2ejvfct0:/etc/kubernetes/manifests# mv ../kube-scheduler.yaml .
root@ncp3cnq6q0djb2ejvfct0:/etc/kubernetes/manifests# kubectl get pods -n kube-system | grep sche
kube-scheduler-192.168.160.103 1/1 Running 0 80m
kube-scheduler-192.168.161.127 0/1 Running 1 2s
kube-scheduler-192.168.161.254 1/1 Running 2 106m
scheduler-controller-manager-5479cd5fbf-8bhgk 1/1 Running 0 104d
scheduler-controller-manager-5479cd5fbf-lgpqz 1/1 Running 0 104d
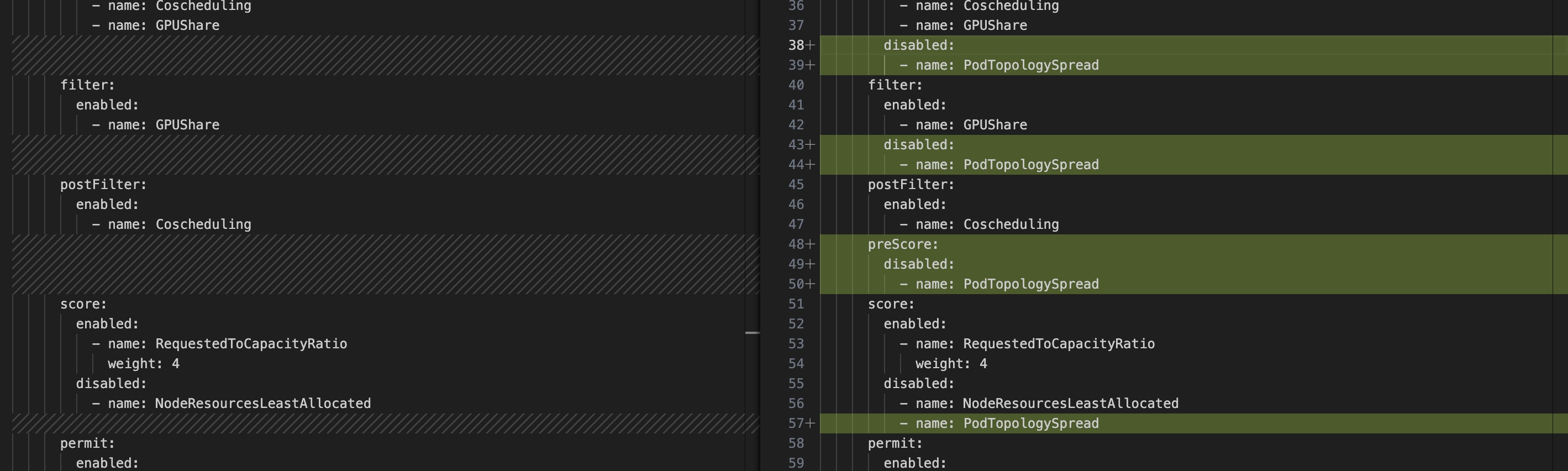
效果
启动很快啦
- 现在10s内启动500个ide,全部启动成功running耗时61左右,之前是5分28s。
- 10s内启动 300 个ide,全部启动成功running耗时44s左右,之前是3分22s。
ws-cr490ueon2flis42a6kg-656b5d498-wfmnm 1/1 Running 0 77s 172.16.37.222 192.168.161.191 <none> <none>
ws-cr490ueon2flis42a6lg-74c75fc6bb-vrnsr 1/1 Running 0 77s 172.16.86.238 192.168.161.64 <none> <none>
ws-cr490ueon2flis42a6mg-7c677b94cc-ntwdk 1/1 Running 0 77s 172.16.59.121 192.168.160.206 <none> <none>
ws-cr490ueon2flis42a6og-784695b496-flskx 1/1 Running 0 77s 172.16.59.53 192.168.160.206 <none> <none>
ws-cr490ueon2flis42a6pg-5fb44dc64d-7c8lx 1/1 Running 0 77s 172.16.87.186 192.168.160.198 <none> <none>
ws-cr490ueon2flis42a6qg-5d74677688-z87qq 1/1 Running 0 76s 172.16.54.202 192.168.161.65 <none> <none>
ws-cr490ueon2flis42a73g-dc8d4cc75-tqp92 1/1 Running 0 77s 172.16.86.237 192.168.161.64 <none> <none>